Transformer
- Attention機構を中心とした機械学習の事。
- Transformerは効率的な総当たりを可能にした
- Transformer以前はGPUを自然言語処理に効率的に適用できていなかった。前後に行きつ戻りつしながら意味や指示語、代名詞等を扱う必要があったため、並列計算と相性が良くなかった。
- 自然言語ではRNNと呼ばれる時系列を扱うための構造を用いるのが普通であり、順序による依存関係を考慮する必要があるため、複数の依存関係間での調節(待ち)が発生し、並列化しにくくなっていた。
- これを打破する機構がAttentoin機構。文章中の単語に粗油店を充てることでその単語と関係するあらゆるつながりを文章中で見つける方法。
- メモリ上の文章はあたかも画像のように扱えるため、並列計算を当てはめることができるようになった。
- さらに、全結合によりテキストの相互参照による重み関係のみを学習すればよいため、一般的な教師あり学習が必ずしも必要ではなくなった。
- これ以前は自然言語の学習は簡単に評価できないため、学習データの一部を教師データとしその中でテストを行い問題と正解を教える必要があった。この問題と正解のペアを作成するコストが非常に高く問題だった。
- 全結合が利用できれば、いわゆる穴埋め問題に帰結可能なため、あらゆるテキストがほぼコストゼロで学習データになりうる(自己教師あり学習)。
- Transformerを利用したBERTでは主に2つの学習方法をとる
- いわゆる穴埋めを行うMasked Language Modeling(MLM)
- 元の学習データから簡単に作成できる
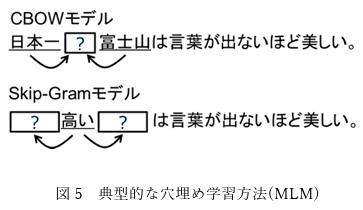
- 文章の近さを評価するNext Sentence Prediction(NSP)
- 2つの文章を比べて次に来る文章として適切か否かを判定する学習

- パラメータが多ければ、学習時に参照範囲を広げることができ、性能が向上する。
自然言語モデル
- Transformerでは文書中の特定の位置での単語の出現確立を前後の単語との相互参照を含めて決めることにより、確率ベースで扱うことでモデルは構成されている。
Zero(Few)-Shot学習
- 事前学習モデルには、学習データ内のテキストに記述されたすべて の参照関係が含まれるため、例示が無いもしくは一例二例の提示のみでドメインチュ ーニングが可能であり、幅広い範囲での任意のタスク出力が可能。
画像への応用
- Transformerは元々自然言語祖y理のための機械学習手法であったが、画像の分野でも有用性が示されている。この分野は*Vision Transformer(ViT)*と呼ばれる。
参考にしたドキュメント